Рассказываем про 12 программ, приложений и нейросетей для распознавания текста
Автор: Валентин Орлов
|
3.9
Оценок: 378(Ваша: )
Дата публикации: 22 июля 2025
С оцифрованной страницей нельзя работать как с обычным документом. Без специальной обработки быстрый поиск, выделение, копирование и редактирование текстовой информации доступны не будут. Проблема решается с помощью метода OCR. Рассказываем, в чем особенности технологии и в каких программах для распознавания текста с картинки она реализована.
OCR (Optical Character Recognition) — оптическое распознавание символов. Технология анализирует изображение, а затем автоматически подставляет к соответствующим визуальным образам буквы, цифры, математические и другие символы.
Есть несколько алгоритмов такой обработки документов:
Текст заменяет изначальное изображение — результат напоминает страницу в документе Word и аналогичных офисных приложениях.
Текст накладывается на отдельный и внешне незаметный слой — визуально сохраняется оформление печатного или электронного оригинала.
Дополнительно запускается интеллектуальная обработка — она различает специфические шрифты и понимает, что пятна, потертости и другие дефекты не являются частью печатных символов (например, «О» не превращается в «Q»).
Полученный текст сразу извлекается в отдельный файл — TXT, RTF или в популярные форматы Microsoft Office.
Важно понимать: технически сканирование мало чем отличается от фотографирования на цифровые камеры. В обоих случаях по итогу получается графический файл. Это актуально и для отсканированных PDF-файлов. Каждый лист в нем изначально представляет собой изображение. Чтобы вы смогли полноценно взаимодействовать с содержанием (а не только читать его), нужно выполнить OCR. Далее необходимо сохранить документ в подходящем текстовом формате, например, в PDF. Если экспортируете в JPEG или PNG, результат распознавания будет утрачен — снова получите изображение.
Сейчас доступно много программ для распознавания текста в PDF и на фотографиях. Для обзора мы выбрали 12 самых интересных решений. При дальнейшем разборе мы уделяли особое внимание нескольким критериям.
Поддерживаемые форматы: JPG, PNG, TIFF, PDF, взаимодействие со сканерами.
Типовые ошибки: разрывы между словами и символами, неправильное определение кодировки (после копирования вставляется нечитаемый набор знаков).
Что важно при работе: наличие удобных инструментов, высокая точность распознавания, внимание к вопросам безопасности.
Какие выбирают OCR-программы для ПК
Десктопные приложения превосходят ПО для других платформ по удобству работы и набору полезных функций. Для проверки качества распознавания этим и другим софтом мы будем использовать одинаковый материал — скан книжной страницы. Шрифт здесь самый обычный, но типографская краска немного выцвела — это поможет определить, насколько совершенны алгоритмы OCR. После сканирования исходный файл сохранен в JPEG.
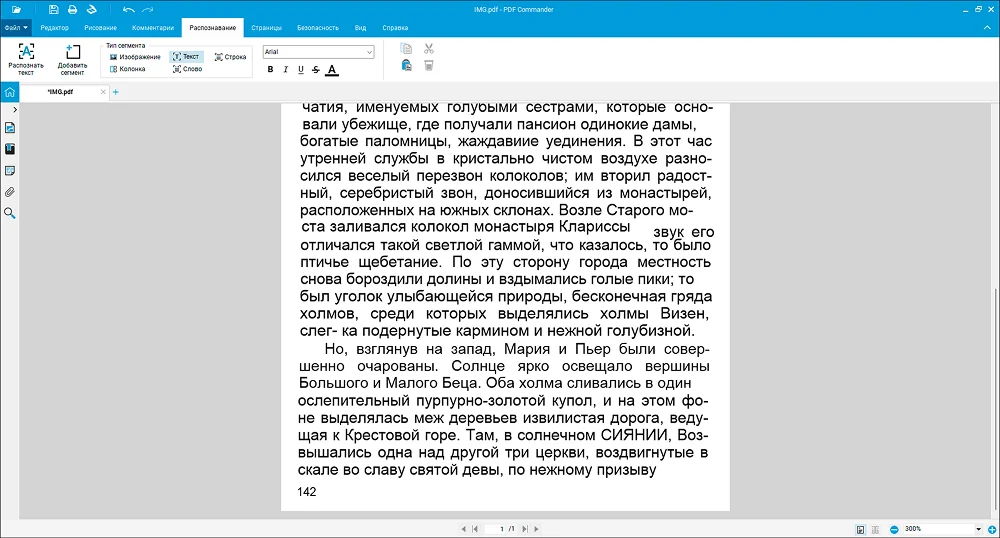
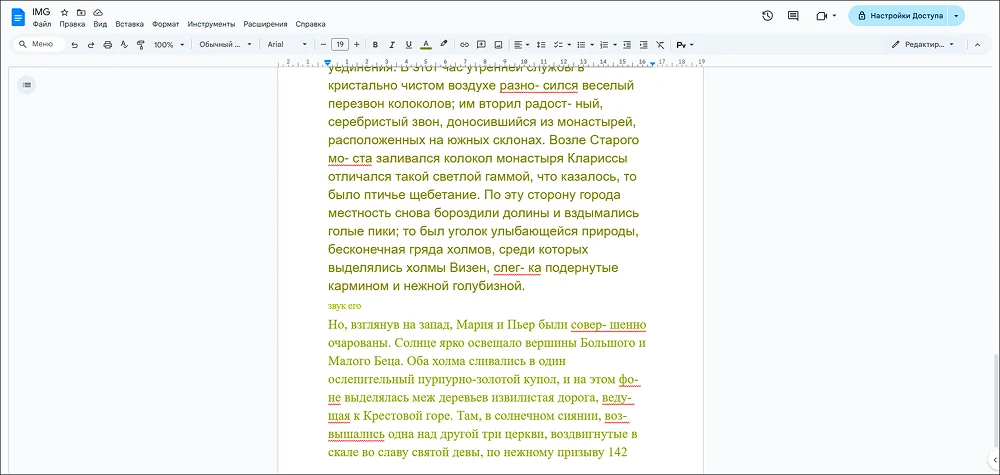
PDF-редактор от российских разработчиков. В нем реализована поддержка технологии OCR для более чем 100 языков. По умолчанию установлены словари для английского и русского. При необходимости в любой момент можно скачать дополнительные языковые пакеты. Есть несколько режимов распознавания. Алгоритм может обрабатывать весь отсканированный документ, выбранный фрагмент страницы, слово или строку, преобразовывать содержимое в текстовый файл или помещать его на специальный слой. Поддерживаются колонки и таблицы.
У PDF-редактора есть несколько преимуществ перед облачным и браузерным софтом:
Полная работоспособность программы сохраняется, когда соединение с интернетом отсутствует или частично нестабильно.
Данные не покидают ваш компьютер (не пересылаются на внешние сервера), что особенно важно при работе с конфиденциальной информацией.
Можно обрабатывать материалы, в которых сотни и даже тысячи страниц.
Задействуются только мощности ПК. Онлайн-сервисы иногда используют технологию нейросетей. В этом случае соответствующие вычисления производятся на серверах. Чтобы компенсировать расходы, разработчики вводят тарификацию по объему работы. Если пользователь выходит за лимиты бесплатной версии или выбранного тарифа, ему приходится доплачивать.
доступна работа с цифровыми подписями российских стандартов;
можно настраивать доступ к PDF-файлу с помощью паролей;
поддерживает наиболее распространенные графические форматы — JPEG, TIFF, PNG, BMP, GIF;
предусмотрен экспорт в TXT, RTF, XLS, DOCX.
Минусы:
есть версии только для Windows и Linux.
Для наглядности обработка выполнялась с преобразованием в редактируемый текст. Алгоритм точно распознал содержимое страницы — есть только незначительные «опечатки», которые легко исправить ручным вводом.
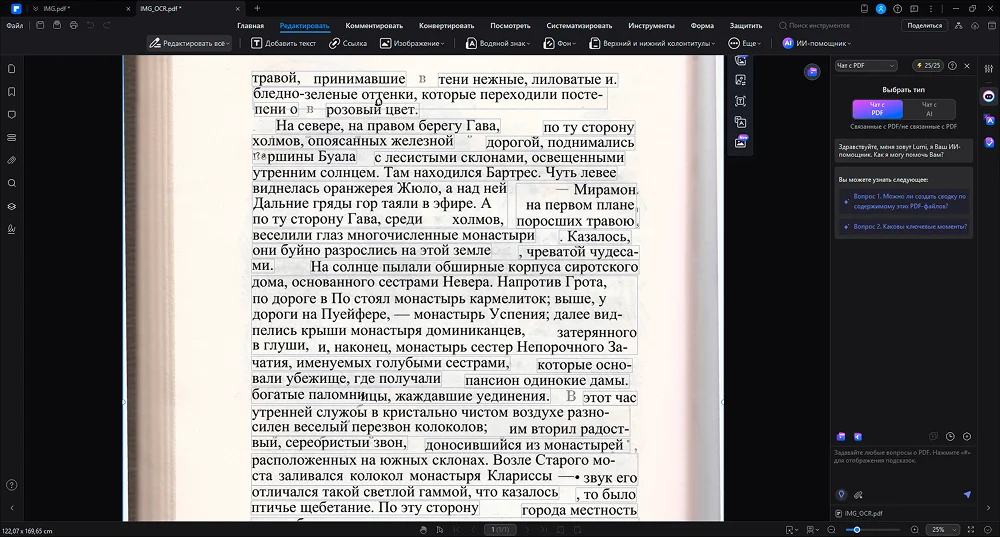
PDF-редактор с собственной нейросетью. Искусственный интеллект может автоматически исправить ошибки OCR, выполнить перевод на другой язык или подготовить краткий пересказ содержания. Есть отдельный режим извлечения данных из электронных таблиц.
Плюсы:
экспорт в ePUB и форматы Word, Excel, PowerPoint;
создание и заполнение электронных форм;
опция пакетной обработки нескольких файлов за раз.
Минусы:
в пробной версии приложение фактически превращается в просмотрщик — почти все связанные с редактированием инструменты (включая OCR) блокируются;
подписка не дает безлимитный доступ к инструменту с ИИ — пользователь получает некоторое количество кредитов на баланс;
для полной функциональности необходимо постоянное соединение с интернетом.
PDFelement пропустил некоторые предлоги, добавил лишние символы и некорректно определил интервалы между словами.
Бесплатная программа для оптического распознавания текстов с фото для операционной системы Windows. Содержимое страницы автоматически извлекается на панель для ввода данных в правой части окна. В ней можно вносить правки и копировать текст.
Плюсы:
опция поворота страниц;
высокая скорость обработки;
может извлекать содержимое сразу из нескольких изображений.
Минусы:
работает только с локализационными пакетами, которые есть в самой ОС. Во многих случаях не получится добавить другие словари;
интерфейс без перевода на русский;
не может экспортировать текстовое наполнение в какой-либо файл.
Алгоритм допустил минимальное количество ошибок. Проблемой стали знаки переноса слов, но это скорее особенности оригинала.
Минималистичная программа для считывания текста с фото. Содержимое помещается на панель справа. Там его можно редактировать и копировать.
Плюсы:
результат можно напрямую переслать по электронной почте;
доступен пакетный режим;
поддерживает свыше 100 языков.
Минусы:
на бесплатной лицензии можно преобразовывать изображения только 5 раз в сутки;
интерфейс без русификации;
фактически нет никаких настроек — только выбор цветовой схемы окна.
Приложение точно распознало большую часть текста, но добавило несколько лишних слов.
Какие есть онлайн-варианты
Поддержка технологии OCR есть в некоторых браузерных программах. Сначала мы остановимся на двух неочевидных вариантах, после чего проверим возможности двух популярных онлайн-сервисов.
Облачная экосистема от Google. В нее входит хранилище файлов и офисный пакет веб-приложений. OCR предусмотрено в текстовом редакторе. Необходимо загрузить изображение в облако, кликнуть по нему правой кнопкой мыши и выбрать «Открыть с помощью» → «Google Документы». Все дальнейшие действия производятся автоматически. Сервис создаст новый документ, импортирует в него исходник и извлечет содержимое — оно добавится как обычный текст.
Плюсы:
автоматически определяет большинство из современных языков, включая русский;
поддерживает PDF, JPEG, GIF и PNG;
в реальном времени сохраняет все изменения в облаке. Если выставить соответствующие параметры приватности, к материалам смогут получить доступ несколько пользователей. Это удобно при организации рабочих процессов в командах.
Минусы:
размер файлов ограничен 2 МБ;
не гарантируется корректное определение надписей, набранных специфическим шрифтом;
обычно пропускает (не распознает) колонки, сноски и таблицы.
Алгоритм добавил ненужные слова, подобрал странное форматирование и у него возникли проблемы с обработкой переносов. Впрочем, все недочеты быстро устраняются вручную.
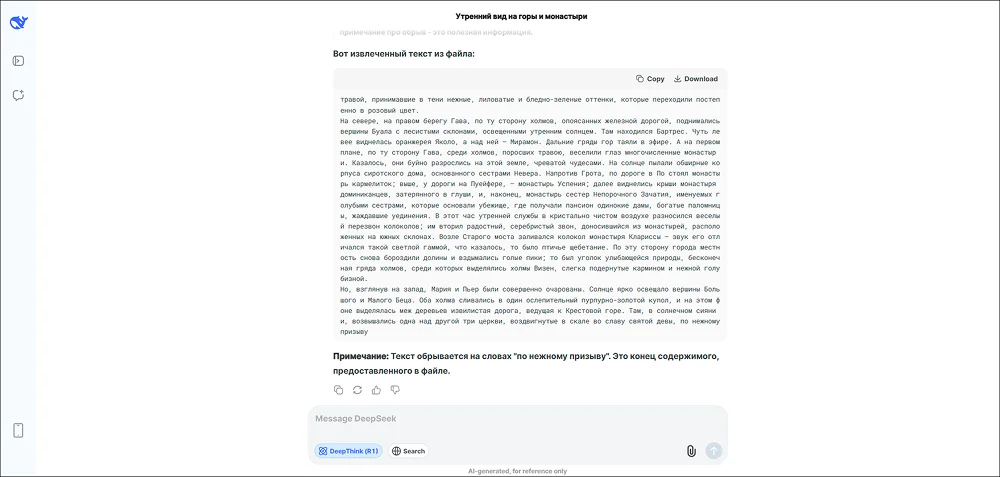
Функционал некоторых сервисов с ИИ позволяет использовать их как OCR-программу для сканирования текста с фото. Для этой задачи подходит DeepSeek. Она существует в виде онлайн-сервиса и программного обеспечения для мобильных устройств. Чтобы начать OCR, достаточно прикрепить файл исходника или снимок экрана к сообщению и обозначить задачу (например, «извлеки текст»).
Плюсы:
к одному заданию можно прикреплять до 50 файлов по 100 МБ каждый;
онлайн-сервис и одноименное приложение для смартфонов пока полностью бесплатны;
результат можно скачать в виде TXT-файла.
Минусы:
обработка выполняется относительно долго — на одну страницу уходит около 20 секунд и больше;
ИИ старается корректировать ошибки, но иногда делает это неправильно. Причем он не оставляет случайный набор символов, который будет подчеркиваться в любом редакторе с автопроверкой орфографии, а заменяет их на похожие слова. Чтобы обнаружить ошибку, придется самостоятельно перечитывать результаты и сверять их с оригиналом;
исходная структура оформления не сохраняется.
ИИ не допустил ошибок и корректно исправил все переносы. Можно заметить, что некоторые слова в конце строки обрезаются. Это особенность интерфейса DeepSeek. Если перенести текст в редактор, соответствующие слова отображаются правильно.
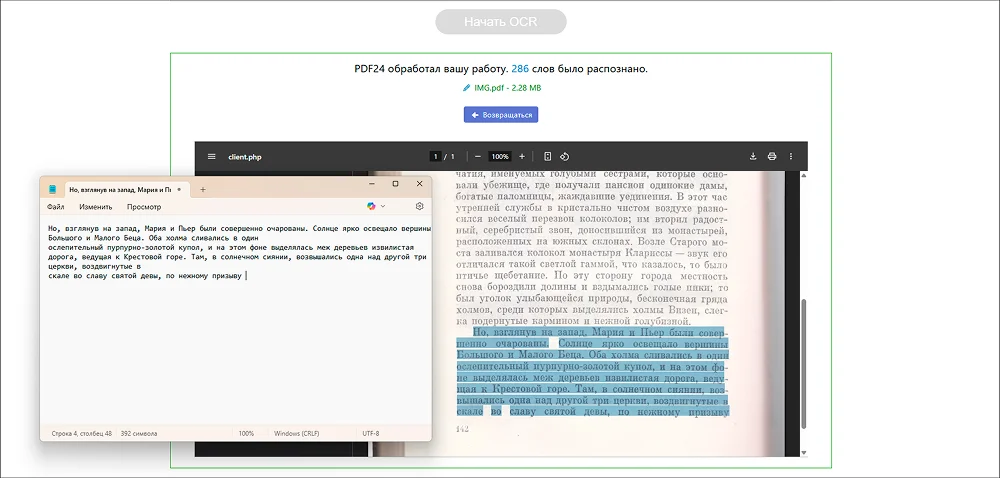
Сайт с разнообразными инструментами для работы с PDF-файлами. Одна из функций отвечает за OCR. Она работает с изображениями и PDF. Распознанное содержание помещается на невидимый слой. Его можно выделять и копировать.
Плюсы:
поддерживает десятки языков;
умеет автоматически убирать артефакты (например, пятна, посторонние надписи) и фон страниц;
одновременно можно обрабатывать несколько файлов.
Минусы:
экспортирует только в PDF;
если потребуется выполнить другие действия (кадрирование, добавление нумерации, водяного знака или что-то еще), придется сначала скачать промежуточный результат, а затем повторно загрузить его в другом инструменте;
периодически выводит баннеры с рекламой.
PDF24 верно распознал слова и убрал переносы в них. Однако появились разрывы строк — они заметны, если скопировать любой фрагмент в сторонний редактор.
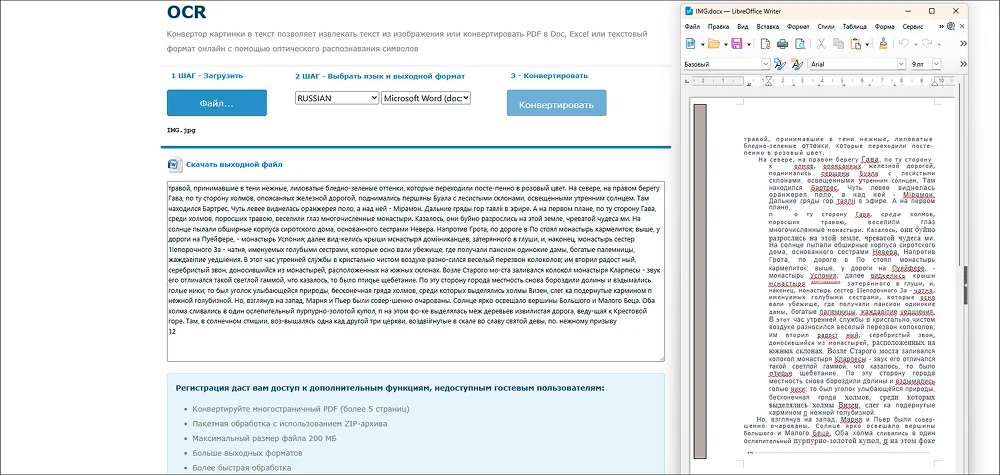
Браузерная программа для распознавания отсканированного текста. Исходные данные получает из загруженных изображений или PDF-файлов. Результат выводится на панели предпросмотра и экспортируется в выбранном формате.
без регистрации размер исходников ограничен 15 МБ;
может показывать рекламу;
не сохраняет исходное форматирование.
Если ориентироваться на область предпросмотра, заметны ошибки. В итоговом DOCX-файле ситуация гораздо хуже. Сервис добавил лишние отступы и блоки, неправильно настроил интервалы между словами и размер шрифта.
Что делать, если есть только телефон
По своим возможностям мобильные девайсы постепенно приближаются к компьютерам. Для iOS и Android выпущено много софта с OCR, а благодаря встроенной камере, самим гаджетом легко сканировать документы.
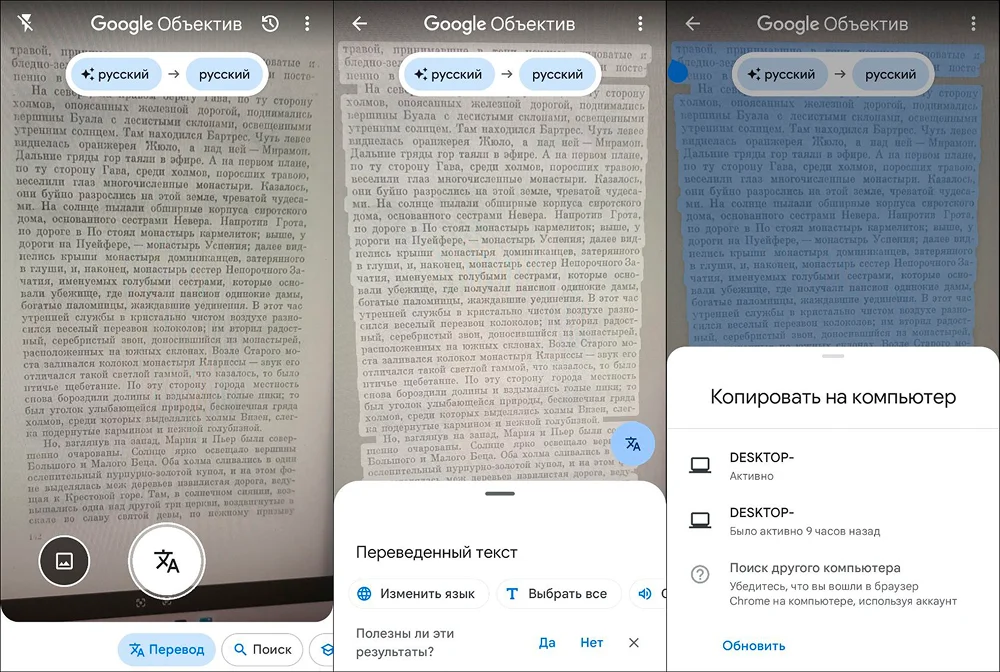
Программа для компьютерного перевода и распознавания текстов. Получает исходные данные через камеру смартфона. Можно сфотографировать страницу бумажного документа, а затем скопировать ее наполнение в мессенджер или редактор. Если перевод не нужен, необходимо установить одинаковый язык оригинала и результата.
Плюсы:
полностью бесплатный аналог OCR-софта;
при наличии учетной записи Google и браузера Chrome может пересылать извлеченный результат на компьютер — текст автоматически помещается в буфер обмена;
поддерживает большинство из языков, включая искусственные (например, эсперанто).
Минусы:
неудобно взаимодействовать с многостраничными материалами. Извлекаемые данные не помещаются в промежуточный файл, их приходится копировать и добавлять вручную;
нет экспорта в редактируемые текстовые форматы;
будет сложно оцифровывать листы крупнее А4.
Приложение без ошибок извлекло содержание страницы, обнаружило компьютер и переслало на него результат.
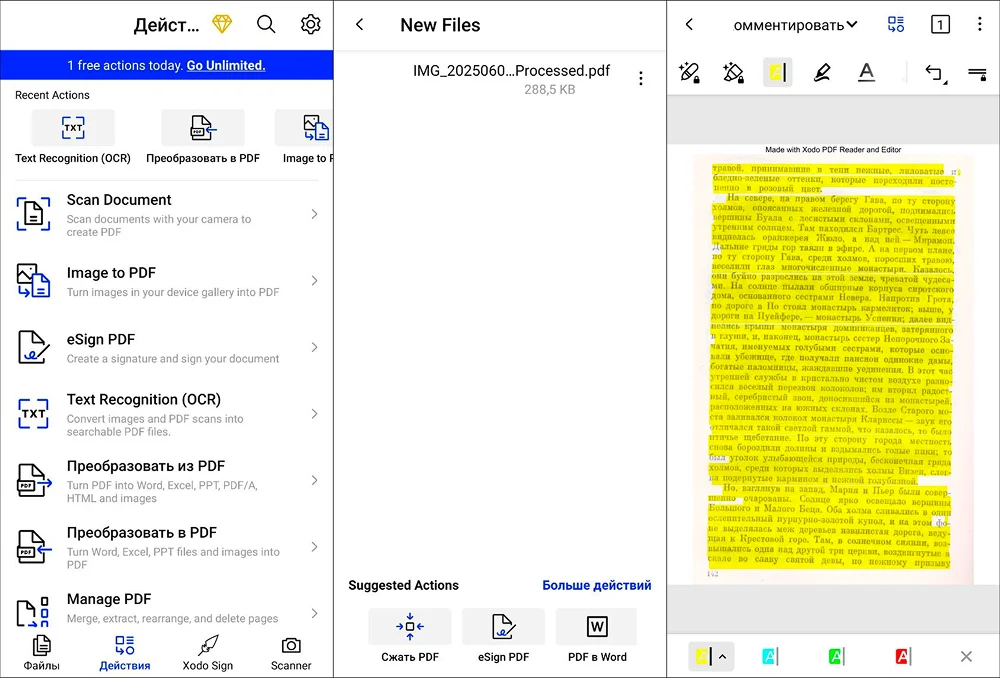
PDF-редактор для телефонов и планшетов. По набору инструментов приближается к аналогичному десктопному софту. OCR действует в автоматическом режиме. Пользователю остается только добавлять исходные фото и документы и запускать обработку.
Плюсы:
есть собственное облачное хранилище;
существуют версии для ПК и браузера;
нейросеть для кратких пересказов и проверки орфографии.
Минусы:
бесплатно можно совершать всего одно действие по редактированию в день;
неполный перевод интерфейса;
высокая стоимость подписки — от 1090 руб. ежемесячно.
Редактор поместил распознанный текст на дополнительный слой. После выделения содержимого, можно заметить, что отдельные символы не были обработаны.
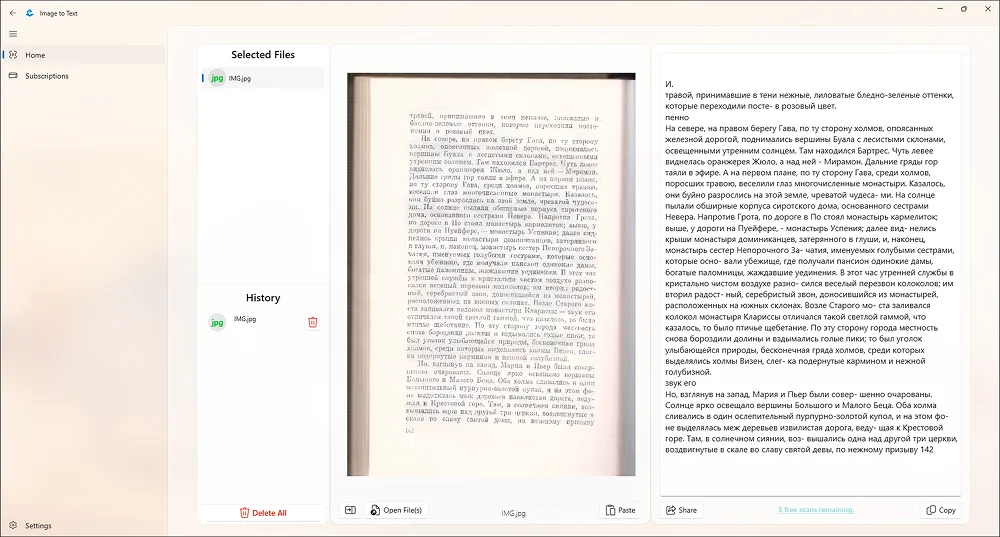
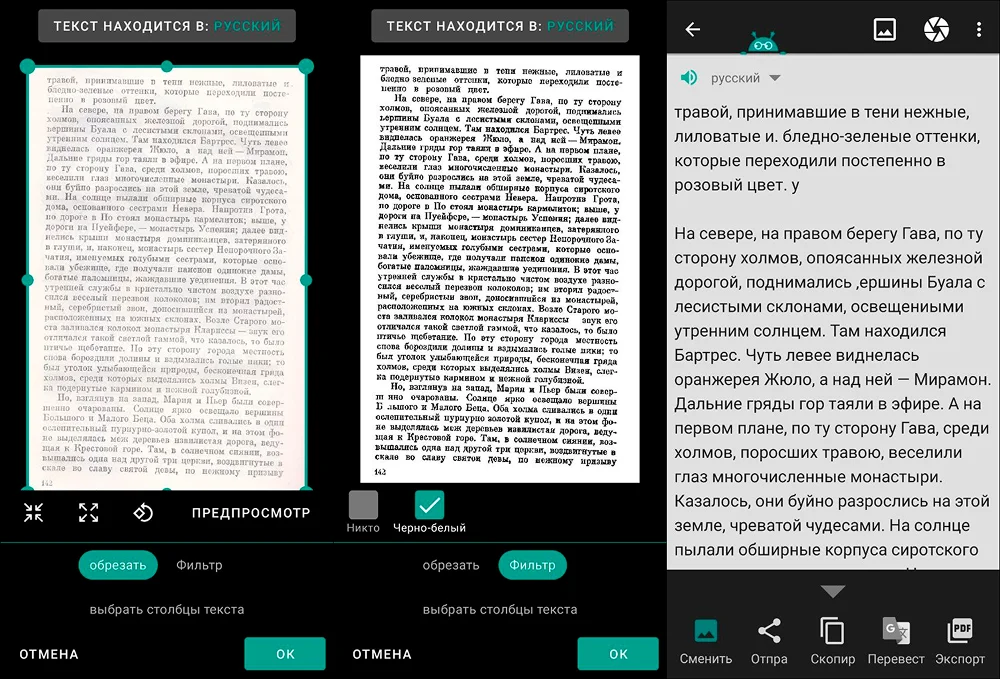
Приложение для преобразования изображений в тексты. Исходный снимок можно получить через камеру телефона либо импортировать (например, предварительно сделать через софт для создания скриншотов). Язык алгоритмы определяют автоматически.
Плюсы:
опция для настройки качества изображения. Можно преобразовать фотографию страниц в черно-белые снимки, что повысит точность обработки, поскольку текст станет более контрастным;
доступно более 110 языков;
функция перевода.
Минусы:
нет дополнительных инструментов для форматирования результата;
возможность экспорта только в виде PDF-файла;
минимальный набор настроек.
Программа не допустила серьезных ошибок. Она лишь добавила несколько случайных букв в конце абзацев.
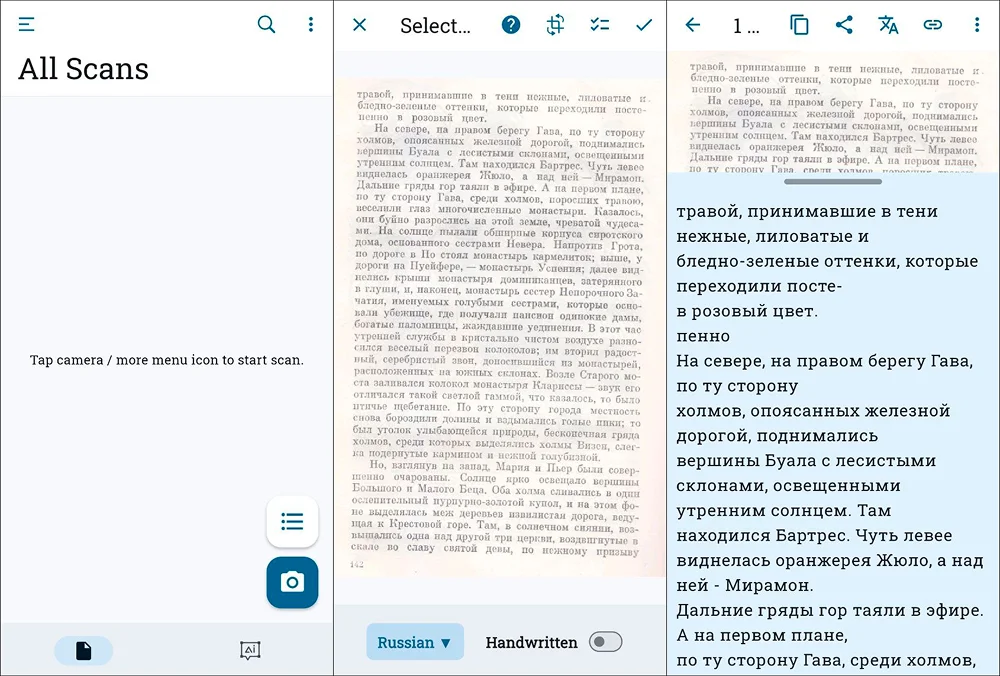
Простое приложение для распознавания текстовых блоков. Работает с фотографиями, сделанными на камеру устройства через саму программу. Также можно загружать существующие графические изображения.
Плюсы:
поддерживает 92 языка;
распознает рукописные надписи;
функция пакетного сканирования.
Минусы:
интерфейс на английском;
нельзя менять форматирование результата;
опция перевода в действительности лишь открывает Google Translate.
Алгоритм перепутал местами некоторые строки, но не исказил слова.
Сравнительная таблица: кратко, наглядно, осталось только выбрать
Облачное хранение с доступом для разных пользователей
Можно прикреплять до 50 файлов до 100 МБ каждый
Пакетный режим распознавания
7 форматов для экспорта
Пересылка извлеченного текста на компьютер
Пакетный режим распознавания
Функция перевода
Пакетное сканирование
Подведем итоги
Мы протестировали программы для распознавания текстов для сканеров, PDF-документов и фотографий листов. Среди этого софта есть весьма неожиданные решения, такие как нейросеть DeepSeek или мобильное приложение Google Lens. Однако, на наш взгляд, удобнее всего OCR-функция реализована в десктопном редакторе PDF Commander. Он поддерживает сканирование, импорт изображений и документов. Есть режим обработки текстовых столбцов, который подходит и для таблиц. Сразу после распознавания можно внести нужные правки и настроить форматирование.
Ответы на часто задаваемые вопросы
Чем отличается OCR от ICR и OMR?
Это разновидности технологии оптического распознавания (OCR), но для более узких задач. ICR предназначено для преобразования рукописных текстов в электронный вид. С помощью OMR считываются данные с различных бумажных форм, например, из бланков с ответами.
Как распознать текст с многоколонного скана или брошюры?
Воспользуйтесь PDF Commander. Для этого в нем есть специальный режим OCR.
Как распознать отсканированную таблицу?
В некоторых программах, например, в PDF Commander предусмотрена отдельная опция.



 3.9
Оценок: 378
(Ваша: )
3.9
Оценок: 378
(Ваша: )
 Дата публикации: 22 июля 2025
Дата публикации: 22 июля 2025











Оставьте ваш комментарий